




Pelo menos 100 instâncias de modelos maliciosos de IA ML foram encontradas na plataforma Hugging Face. Alguns desses modelos maliciosos podem executar código na máquina da vítima, proporcionando aos invasores um backdoor persistente.
Modelos maliciosos de IA na plataforma Hugging Face
Hugging Face é uma empresa de tecnologia envolvida em inteligência artificial (IA), processamento de linguagem natural (PNL) e aprendizado de máquina (ML), fornecendo uma plataforma onde as comunidades podem colaborar e compartilhar modelos, conjuntos de dados e aplicativos completos.
A equipe de segurança da JFrog descobriu que cerca de cem modelos hospedados na plataforma apresentam funcionalidades maliciosas, representando um risco significativo de violações de dados e ataques de espionagem. Isso acontece apesar das medidas de segurança do Hugging Face, incluindo varredura de malware, pickle e segredos, e exame minucioso da funcionalidade dos modelos para descobrir comportamentos como desserialização insegura.

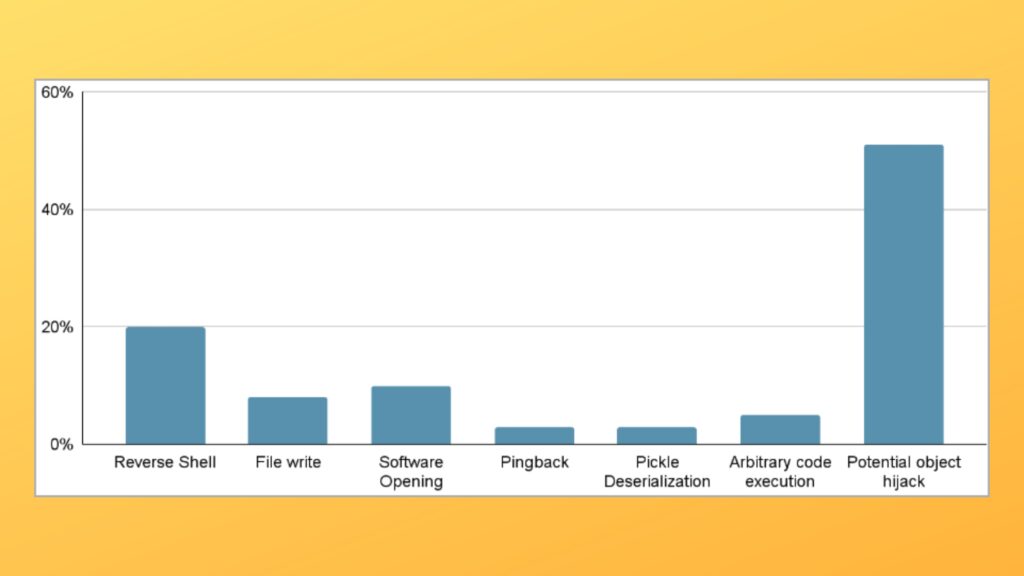
A JFrog desenvolveu e implantou um sistema de varredura avançado para examinar modelos PyTorch e Tensorflow Keras hospedados no Hugging Face, encontrando cem com alguma forma de funcionalidade maliciosa.
É crucial enfatizar que quando nos referimos a “modelos maliciosos”, denotamos especificamente aqueles que abrigam cargas úteis reais e prejudiciais.
Esta contagem exclui falsos positivos, garantindo uma representação genuína da distribuição de esforços para a produção de modelos maliciosos para PyTorch e Tensorflow no Hugging Face.
Um caso destacado de um modelo PyTorch que foi carregado recentemente por um usuário chamado “baller423” e que desde então foi removido do HuggingFace continha uma carga útil que lhe dava a capacidade de estabelecer um shell reverso para um host especificado (210.117.212.93), aponta o Bleeping Computer.
A carga maliciosa usou o método “reduce” do módulo pickle do Python para executar código arbitrário ao carregar um arquivo de modelo PyTorch, evitando a detecção ao incorporar o código malicioso no processo de serialização confiável.
JFrog encontrou a mesma carga conectando-se a outros endereços IP em instâncias separadas, com as evidências sugerindo a possibilidade de seus operadores serem pesquisadores de IA em vez de hackers. No entanto, a sua experimentação ainda era arriscada e inadequada. Os analistas implantaram um HoneyPot para atrair e analisar a atividade para determinar as reais intenções dos operadores, mas não conseguiram capturar nenhum comando durante o período de conectividade estabelecida (um dia).
Uploads maliciosos
A JFrog diz que alguns dos uploads maliciosos podem fazer parte de pesquisas de segurança destinadas a contornar as medidas de segurança do Hugging Face e coletar recompensas por bugs, mas como os modelos perigosos se tornam disponíveis publicamente, o risco é real e não deve ser subestimado.
Os modelos de AI ML podem representar riscos de segurança significativos e não foram apreciados ou discutidos com a devida diligência pelas partes interessadas e desenvolvedores de tecnologia. As descobertas do JFrog destacam este problema e apelam a uma vigilância elevada e a medidas proativas para proteger o ecossistema de agentes maliciosos.


