
Apenas 3 segundos são necessários para que a nova IA VALL-E, criada pela Microsoft, possa converter texto em fala. E o pior e mais perigoso é que ela pode imitar a voz de qualquer pessoa com base em uma amostra de apenas 3 segundos.
A Microsoft revelou detalhes de sua mais recente incursão no mundo da inteligência artificial. Anunciado como um “modelo de linguagem de codec neural”, o VALL-E é um sistema avançado de conversão de texto em fala (TTS) orientado por IA que, segundo os desenvolvedores, pode ser treinado para falar como qualquer pessoa com base em apenas uma amostra de três segundos de sua voz.
Microsoft cria VALL-E, uma IA de conversão de texto em fala que pode imitar a voz de qualquer pessoa
O resultado é um sistema TTS incrivelmente natural que adota uma abordagem totalmente diferente dos sistemas existentes. Capaz de transmitir tom e emoção melhor do que nunca, o VALL-E soa realisticamente humano, mas há preocupações de que possa ser usado para deepfakes de áudio.
A IA foi construída e treinada usando 60.000 horas de entrada de áudio de milhares de indivíduos, incluindo livros de áudio de domínio público. Trabalhando com uma amostra curta, o VALL-E é capaz de imitar de perto o tom e o timbre de uma voz de uma forma que simplesmente não era possível anteriormente.
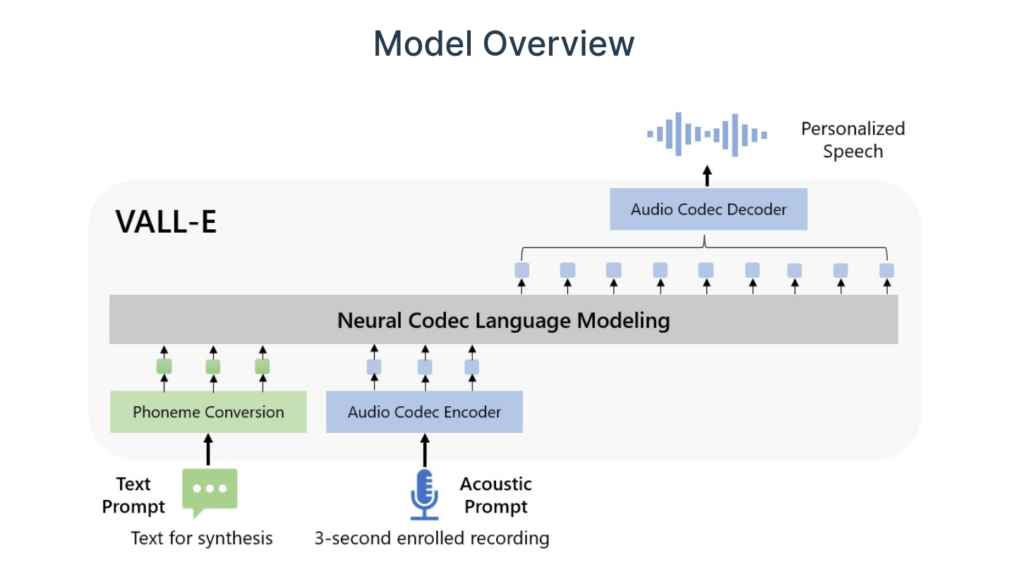
Escrevendo sobre VALL-E, uma equipe de pesquisadores da Microsoft diz:
Apresentamos uma abordagem de modelagem de linguagem para síntese de texto para fala (TTS). Especificamente, treinamos um modelo de linguagem de codec neural (chamado VALL-E) usando códigos discretos derivados de um modelo de codec de áudio neural pronto para uso e consideramos o TTS como uma tarefa de modelagem de linguagem condicional em vez de regressão contínua de sinal como no trabalho anterior. Durante o estágio de pré-treinamento, aumentamos os dados de treinamento TTS para 60 mil horas de fala em inglês, centenas de vezes maiores do que os sistemas existentes. O VALL-E oferece recursos de aprendizado no contexto e pode ser usado para sintetizar fala personalizada de alta qualidade com apenas uma gravação registrada de 3 segundos de um falante invisível como um prompt acústico.
A equipe continua dizendo: “Os resultados do experimento mostram que o VALL-E supera significativamente o sistema TTS zero-shot de última geração em termos de naturalidade da fala e similaridade do locutor. Além disso, descobrimos que o VALL-E pode preservar o emoção do locutor e ambiente acústico do prompt acústico em síntese”.
Você pode descobrir mais na página de demonstração do VALL-E, onde há vários exemplos de como soa com base em várias entradas de treinamento.