Junto com a proliferação de análises de aprendizado de máquina e tecnologias de dados em quase todos os setores, há uma complexidade crescente de tarefas. Ter conjuntos de dados maiores e uma quantidade maior de sistemas para pesquisas baseadas em IA é ótimo, mas enquanto esses fluxos de trabalho se tornam cada vez mais elaborados, mais tempo eles requerem dos pesquisadores para sua configuração e, com isso, menos tempo para conduzirem ciência de dados.
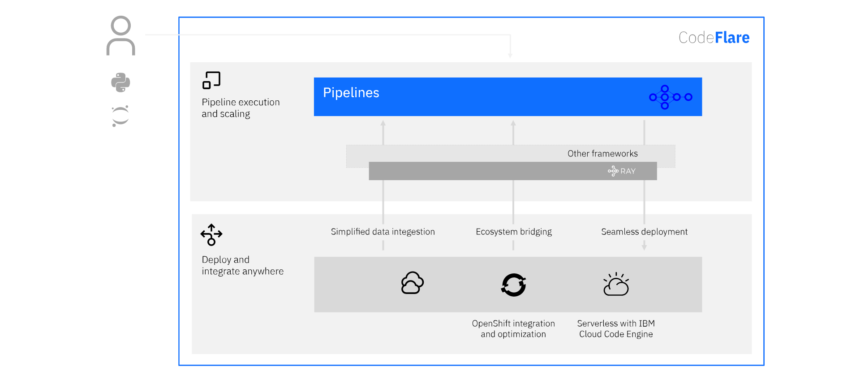
IBM anunciou o CodeFlare , uma estrutura de código aberto destinada a simplificar a integração e o dimensionamento eficiente de big data e fluxos de trabalho de IA na nuvem híbrida. O CodeFlare é construído em Ray, uma estrutura emergente de computação distribuída de código aberto para aplicativos de aprendizado de máquina. O CodeFlare estende os recursos do Ray e adiciona elementos específicos para facilitar o dimensionamento do fluxo de trabalho.
Atualmente, para criar um modelo de aprendizado de máquina, pesquisadores e desenvolvedores devem primeiro treinar e otimizar este modelo. Essas tarefas podem envolver limpeza de dados, extração de recursos e otimização de modelo. O CodeFlare simplifica esse processo usando uma interface baseada em Python, para o que é chamado de pipeline, que simplifica as etapas de integração, paralelização e compartilhamento de dados. O objetivo da nova estrutura é unificar fluxos de pipeline em várias plataformas sem que os cientistas de dados tenham que aprender uma nova linguagem de fluxo de trabalho.
CodeFlare reduz tempo para configurar, executar e escalar testes de aprendizado de máquina

Os pipelines CodeFlare são executados facilmente na nova plataforma serverless da IBM, IBM Cloud Code Engine e Red Hat OpenShift. Os usuários podem implementá-lo em quase qualquer lugar, estendendo os benefícios da plataforma serverless para cientistas de dados e pesquisadores de IA. Também é mais fácil integrar e fazer a ponte com outros ecossistemas nativos na nuvem, fornecendo adaptadores para acionadores de eventos (como a chegada de um novo arquivo), carregando e particionando dados de uma ampla gama de fontes, como armazenamentos de objetos em nuvem, data lakes e sistemas de arquivos distribuídos.
Com o CodeFlare, espera-se que os desenvolvedores não tenham que duplicar seus esforços ou enfrentar a dificuldade de determinar o que os colegas fizeram no passado para colocar um determinado pipeline em execução. Com o CodeFlare, a IBM visa fornecer aos cientistas de dados ferramentas e APIs mais avançadas que possam ser utilizadas de forma mais integrada, permitindo que se concentrem mais em suas pesquisas em andamento e se desliguem da complexidade de configuração e implementação.
E já estamos vendo isso. Por exemplo, quando um usuário aplicou a estrutura para analisar e otimizar aproximadamente 100.000 pipelines para treinar modelos de aprendizado de máquina, o CodeFlare reduziu o tempo de execução de cada pipeline de 4 horas para 15 minutos. Com outros usuários, o CodeFlare diminuir meses de desenvolvimento e permitir que os desenvolvedores lidem com problemas de dados cada vez maiores.
A IBM oferece o open-sourcing CodeFlare junto com uma série de postagens de blog sobre como ele funciona e sobre o que você precisa saber para começar. E este é apenas o começo da jornada que a IBM planeja fazer com o CodeFlare. Começou a aplicar essa tecnologia em temas que estão construindo na IBM, em sua própria pesquisa de inteligência artificial. Continuarão a trabalhar na evolução do CodeFlare para suportar pipelines cada vez mais complexos. Estão planejando fornecer níveis aprimorados de tolerância a falhas e consistência, bem como melhorar a integração e gerenciamento de dados para fontes externas e adicionar suporte para visualização de pipelines.






