Pesquisas recentes revelaram quase duas dúzias de vulnerabilidades em 15 projetos de machine learning (ML) de código aberto, destacando riscos significativos para a infraestrutura de operações de ML. A análise realizada pela empresa de segurança da cadeia de suprimentos de software, JFrog, detalhou essas falhas, que incluem invasões de servidores, escalonamento não autorizado de privilégios e comprometimento da gestão de modelos de ML.
Falhas de segurança em ferramentas de Machine Learning ameaçam integridade de servidores
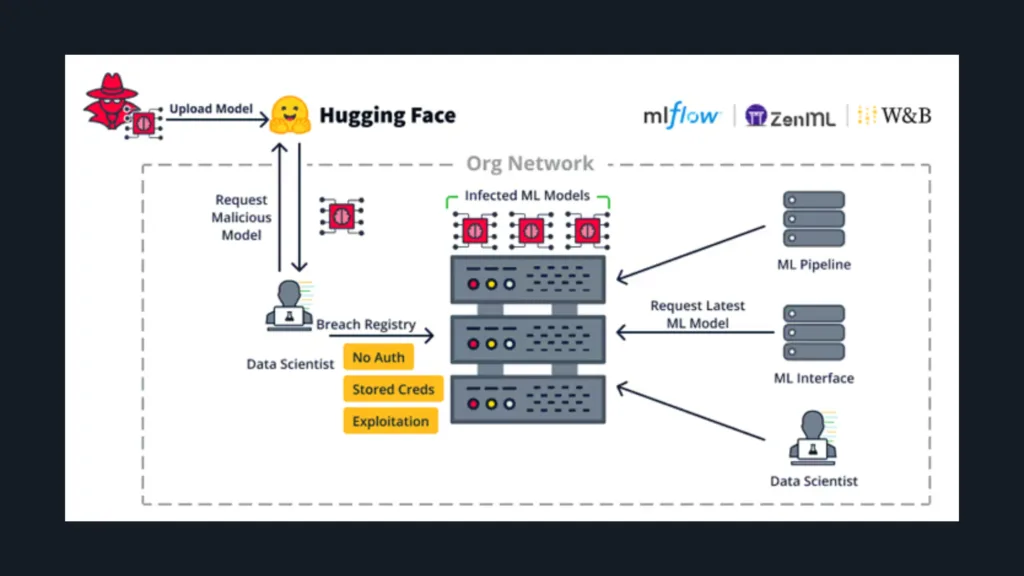
Essas vulnerabilidades afetam tanto o lado do servidor quanto o lado do cliente. De acordo com a JFrog, as falhas do lado do servidor permitem que atacantes assumam o controle de recursos essenciais, como registros de modelos de ML, bancos de dados e pipelines de ML. Dentre os frameworks de ML afetados, destacam-se o Weave, ZenML, Deep Lake, Vanna.AI e Mage AI, cada um vulnerável a explorações críticas que podem interromper os fluxos de trabalho de ML e comprometer a segurança dos dados.
Resumo das principais vulnerabilidades
- Weave ML Toolkit (CVE-2024-7340, CVSS 8.8): Classificada como uma falha de travessia de diretórios, essa vulnerabilidade permite que usuários de baixo privilégio acessem arquivos do sistema, possibilitando a escalada de privilégios ao nível de administrador. O problema foi corrigido na versão 0.50.8.
- ZenML MLOps Framework: Uma falha de controle de acesso no ZenML permite que usuários elevem privilégios de visualizador para administrador, ganhando controle sobre componentes sensíveis como o Secret Store. Embora não tenha recebido um CVE, essa vulnerabilidade é crítica devido ao seu potencial de acesso abrangente.
- Banco de Dados Deep Lake (CVE-2024-6507, CVSS 8.1): Vulnerabilidades de injeção de comando no Deep Lake permitem que atacantes executem comandos do sistema ao fazer upload de datasets do Kaggle, devido à falta de validação adequada de entrada. A versão 3.9.11 já mitiga o problema.
- Vanna.AI (CVE-2024-5565, CVSS 8.1): Uma vulnerabilidade de injeção de prompt pode permitir execução remota de código no servidor anfitrião, representando um risco substancial de exploração remota e controle não autorizado do sistema.
- Framework Mage AI: Várias vulnerabilidades afetam o Mage AI:
- CVE-2024-45187 (CVSS 7.1): Uma falha de atribuição de privilégios que permite a execução remota de código por usuários convidados através do terminal do Mage AI.
- CVE-2024-45188, CVE-2024-45189, CVE-2024-45190 (CVSS 6.5): Múltiplas falhas de travessia de caminho, permitindo que visualizadores acessem arquivos do servidor de forma não autorizada através de requisições específicas, colocando dados em risco.
Riscos relacionados aos pipelines de MLOps
Os pipelines de MLOps, que gerenciam conjuntos de dados, treinamento de modelos e processos de publicação, estão particularmente em risco. De acordo com a JFrog, qualquer comprometimento desses pipelines pode levar a graves violações, como backdoors em modelos ou envenenamento de dados, o que pode resultar na implantação de modelos maliciosos ou na manipulação de dados de treinamento.
Mecanismos de defesa proativa: o framework Mantis
Em resposta a essas vulnerabilidades, acadêmicos da Universidade George Mason introduziram o framework Mantis, uma nova abordagem defensiva que utiliza injeções de prompt para combater ataques cibernéticos baseados em ML. Essa estratégia de defesa passiva e ativa visa desestabilizar as operações dos modelos de linguagem do atacante, incorporando prompts projetados para atrapalhar o modelo do invasor e, em alguns casos, redirecionar o ataque contra seu próprio sistema.
A pesquisa por trás do Mantis destaca sua eficácia em dissuadir ataques automatizados a sistemas de ML, com potenciais aplicações futuras para fortalecer a resiliência de segurança em plataformas de ML e IA.